2024. 1. 21. 07:07ㆍ코딩 도구/LG Aimers
LG Aimers: AI전문가과정 4차
Module 6. 『딥러닝(Deep Learning)』
ㅇ 교수 : KAIST 주재걸 교수
ㅇ 학습목표
Neural Networks의 한 종류인 딥러닝(Deep Learning)에 대한 기본 개념과 대표적인 모형들의 학습원리를 배우게 됩니다.
이미지와 언어모델 학습을 위한 딥러닝 모델과 학습원리를 배우게 됩니다.
Part 4. Seq2Seq with Attention for Natural Language Understanding and Generation
-Recurrent Neural Networks (RNNs)
• Given a sequence data, we recursively run the same function over time.
• We can process a sequence of vectors 𝐱 by
applying a recurrence formula at every time step:
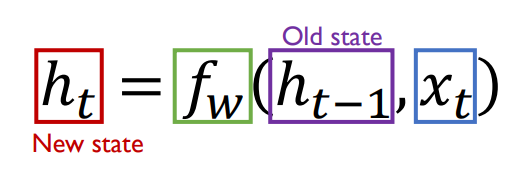
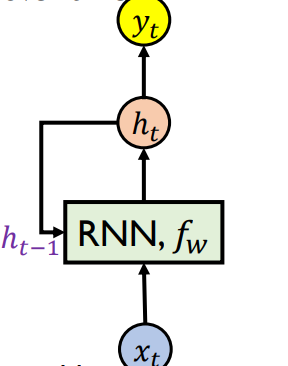
• Optionally, at those time steps we have to predict the target variable, we use ℎ𝑡 as input to the output layer
-Various Problem Settings of RNN-based Sequence Modeling
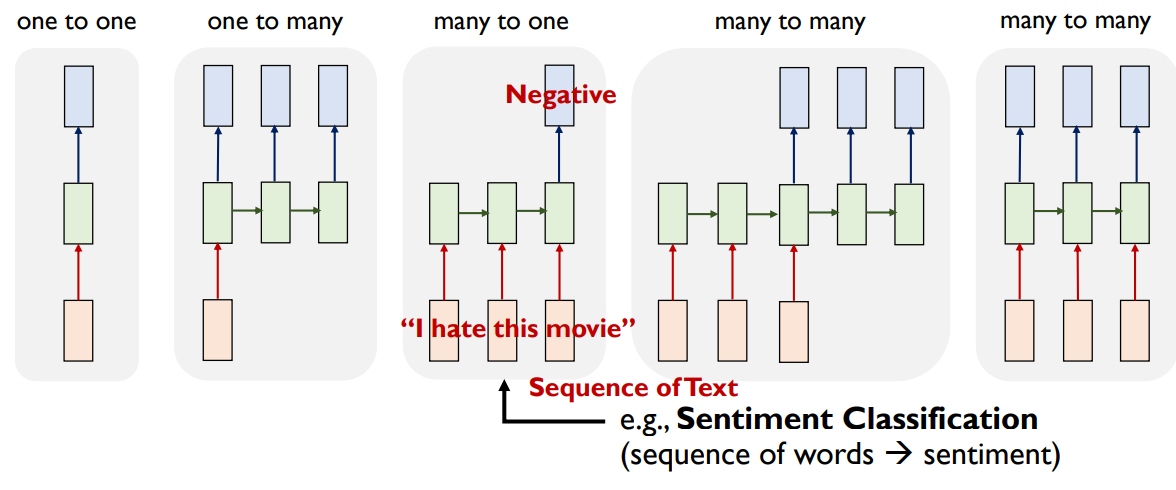
one to one : Vanilla Neural Networks
one to many : e.g., Image Captioning(image → sequence of words)
many to one : e.g., Sentiment Classification (sequence of words → sentiment)
many to many : e.g., Machine Translation
(sequence of words → sequence of words)
many to many : e.g., Video Classification on Frame Level
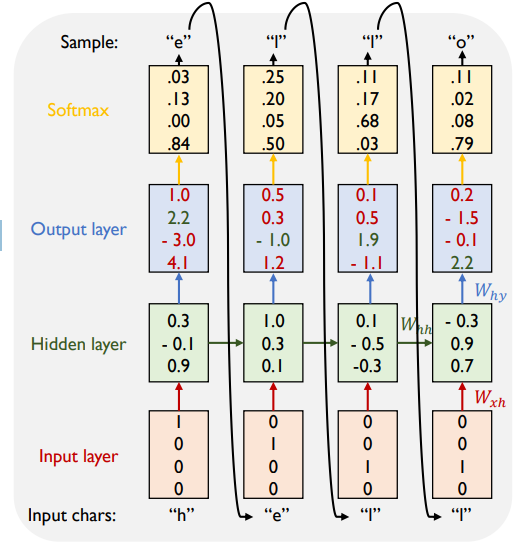
-Character-level Language Model
• Character-level language model example:
• Vocabulary: [h, e, l, o]
• Example training sequence: “hello”
• At test-time sample characters one at a time,
feed back as an input to the model at the next
time step, which is called auto-regressive
model
-Character-level Language Model
• Training an RNN on Shakespeare’s plays
• Training process of RNN
• Results of trained RNN
• A paper written by RNN
• C code generated by RNN
-Gradient Vanishing or Exploding Problem of Vanilla RNNs
• Vanilla RNNs are simple but don’t work very well due to a gradient vanishing or
exploding problem.
• Thus, an advanced RNN models such as LSTM or GRU are often used in practice.
-Long Short-Term Memory (LSTM)
• What is LSTM (Long Short-Term Memory)?
• The repeating module in an LSTM contains four interacting layers
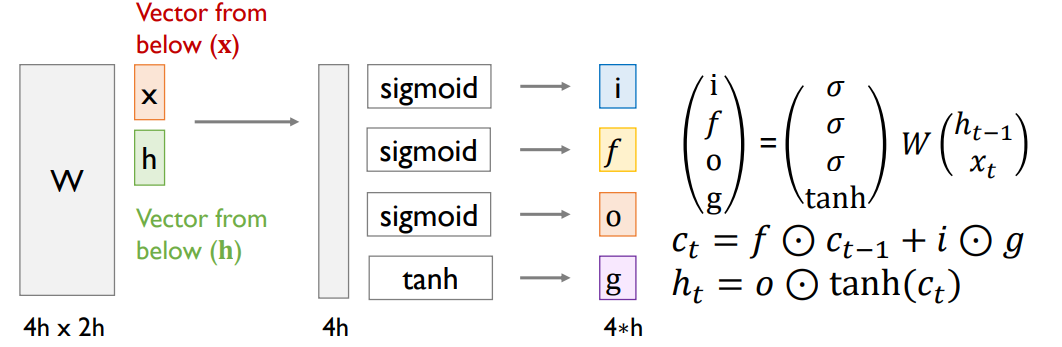
• f: Forget gate, Whether to erase cell
• i: Input gate, Whether to write to cell
• g: Gate gate, How much to write to cell
• o: Output gate, How much to reveal cell
• W: weight (matrix)
• H: hidden state
• c: cell state
• x: input
-Attention is Great!
Attention significantly improves NMT performance
• It is effective to allow the decoder to focus on particular part of the source sequence
Attention solves the bottleneck problem
• Attention allows the decoder to look directly at the source sequence, addressing the bottleneck problem Attention helps with vanishing gradient problem
• Provides a shortcut to faraway states
-Advanced Attention Techniques
Gating (using sigmoid instead of softmax)
• Squeeze-and-excitation networks, gated convolutional networks
Self-attention (serving a general-purpose sequence or set encoder)
• Three important concepts: query, key, and value
• Transformer, BERT, and their variants
-RNN/LSTM Summary
• RNNs allow a lot of flexibility in architecture design
• Vanilla RNNs are simple but don’t work very well
• Common to use LSTM or GRU: their additive interactions improve gradient flow
• Backward flow of gradients in RNN can explode or vanish. Exploding is controlled with gradient clipping. Vanishing is controlled with additive interactions(LSTM)
• Better/simpler architectures are a hot topic of current research
• Better understanding(both theoretical and empirical) is needed.
'코딩 도구 > LG Aimers' 카테고리의 다른 글
| LG Aimers 4기 Self-Supervised Learning & Large-Scale Pre-Trained Models (3) | 2024.01.23 |
|---|---|
| LG Aimers 4기 Transformer (4) | 2024.01.22 |
| LG Aimers 4기 Convolutional Neural Networks and Image Classification (5) | 2024.01.20 |
| LG Aimers 4기 Training Neural Networks (3) | 2024.01.19 |
| LG Aimers 4기 Deep Neural Networks (2) | 2024.01.18 |