2024. 1. 19. 08:01ㆍ코딩 도구/LG Aimers
LG Aimers: AI전문가과정 4차
Module 6. 『딥러닝(Deep Learning)』
ㅇ 교수 : KAIST 주재걸 교수
ㅇ 학습목표
Neural Networks의 한 종류인 딥러닝(Deep Learning)에 대한 기본 개념과 대표적인 모형들의 학습원리를 배우게 됩니다.
이미지와 언어모델 학습을 위한 딥러닝 모델과 학습원리를 배우게 됩니다.
Part 2. Training Neural Networks
-Training Neural Networks via Gradient Descent
Given the optimization problem, min 𝑊
𝐿 (𝑊) , where 𝑊 is the neural network parameters, we optimize 𝑊 using gradient descent approach:
𝑊 ≔ 𝑊 − 𝛼 * 𝑑𝐿(𝑊)/d𝑊
-Poor Convergence Case of Naïve Gradient Descent
Suppose loss function is steep vertically but shallow horizontally:
Q: What is the trajectory along which we converge towards the minimum with SGD?
Very slow progress along flat direction, jitter along steep one
-Backpropagation to Compute Gradient in Neural Networks
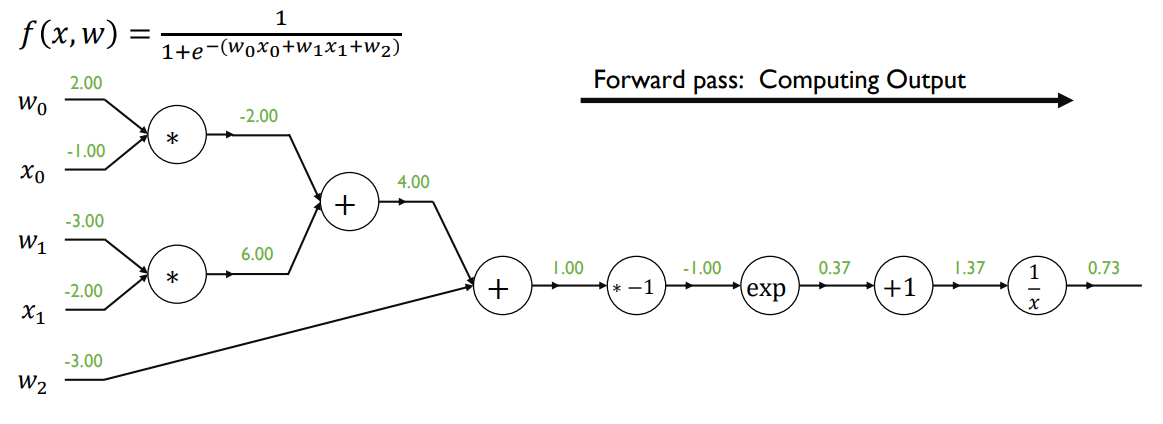
First, given an input data item, compute the loss function value via Forward Propagation
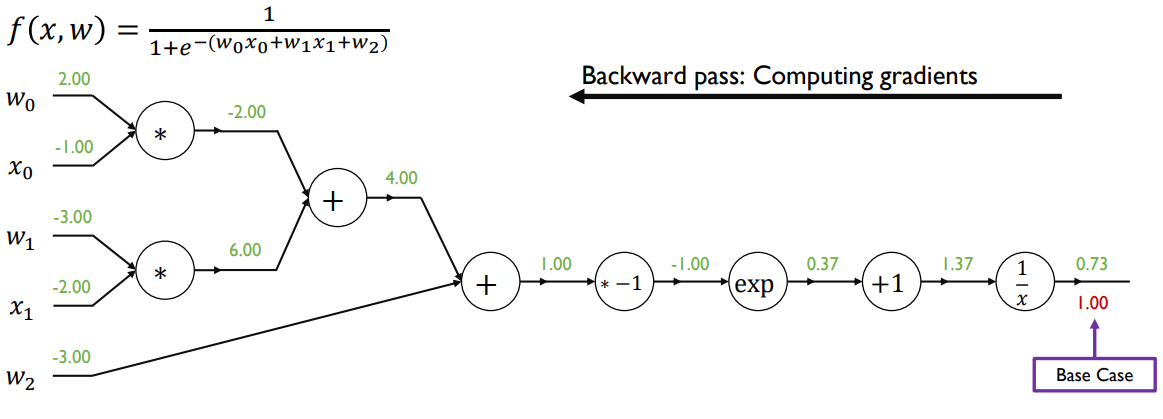
Afterwards, compute the gradient with respect to each neural network parameter via Backpropagation
Finally, update the parameters using gradient descent algorithm
-Computational Graph of Logistic Regression
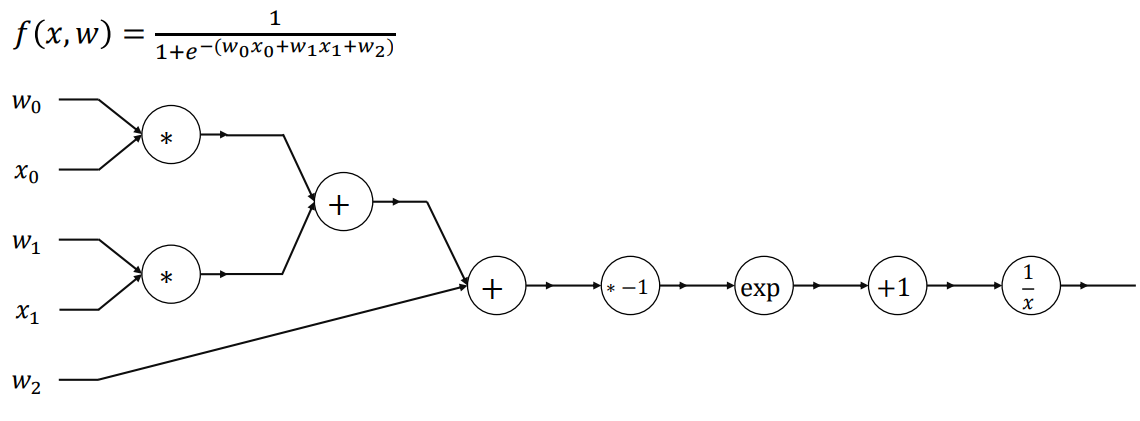
-Forward Propagation of Logistic Regression
-Backpropagation of Logistic Regression
-Sigmoid Activation
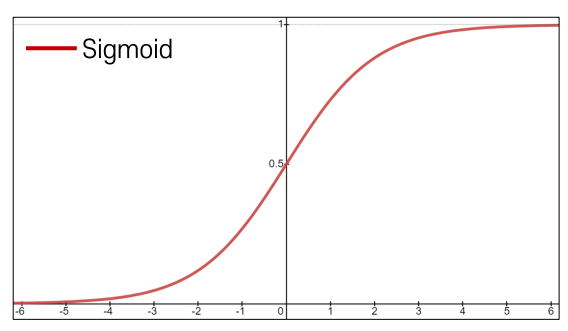
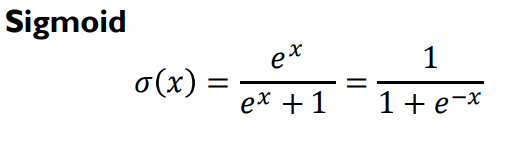
• Maps real numbers in (−∞, ∞) into a range
of [0, 1]
• gives a probabilistic interpretation
-Problems of Sigmoid Activation
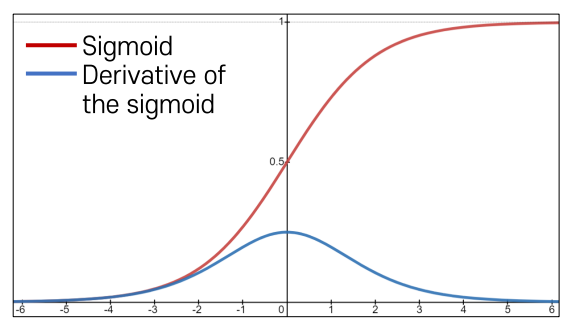
• Saturated neurons kills the gradients
• The gradient value 𝜎 𝑥 ≤1/4 which decreases the gradient during backpropagation, i.e., causing a gradient
vanishing problem
-Tanh Activation
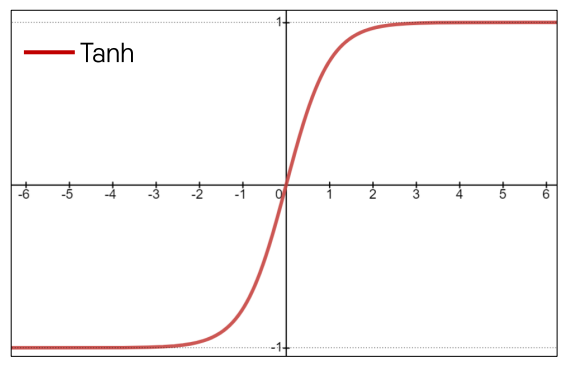
Tanh
• tanh 𝑥 = 2 × sigmoid 𝑥 − 1
• Squashes numbers to range [-1, 1]
Strength
• Zero-centered (average is 0) Weakness
• Still kills gradients when saturated, i.e., still
causing a gradient vanishing problem
-ReLU Activation
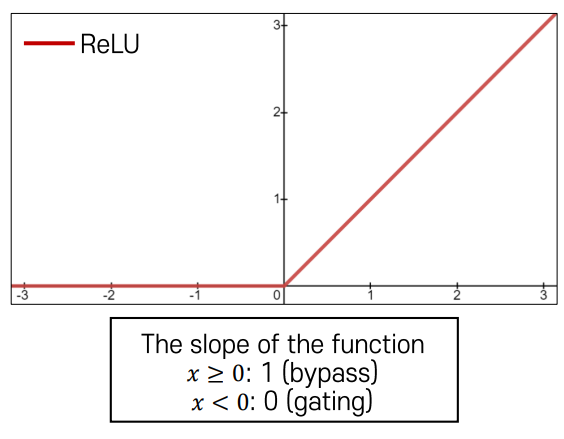
ReLU (Rectified Linear Unit)
• 𝑓(𝑥) = max(0, 𝑥)
Strength
• Does not saturate (in + region)
• Very computationally efficient
• Converge much faster than sigmoid/tanh
Weakness
• Not zero-centered output
• Gradient is completely zero for 𝑥 < 0
Batch Normalization
-Motivation of Batch Normalization
• Saturated gradients when random initialization is done
• The parameters are not updated → Hard to optimize (in red region)
-Definition of Batch Normalization
“You want unit Gaussian activations? just make them so.”
• We consider a batch of activations at some layer to make each dimension unit Gaussian
'코딩 도구 > LG Aimers' 카테고리의 다른 글
| LG Aimers 4기 Seq2Seq , Natural Language Understanding and Generation (2) | 2024.01.21 |
|---|---|
| LG Aimers 4기 Convolutional Neural Networks and Image Classification (5) | 2024.01.20 |
| LG Aimers 4기 Deep Neural Networks (2) | 2024.01.18 |
| LG Aimers 4기 Phase 1 온라인 교육 후기 (0) | 2024.01.17 |
| LG Aimers 4기 인과추론의 다양한 연구 방향 (0) | 2024.01.17 |