2024. 1. 22. 07:00ㆍ코딩 도구/LG Aimers
LG Aimers: AI전문가과정 4차
Module 6. 『딥러닝(Deep Learning)』
ㅇ 교수 : KAIST 주재걸 교수
ㅇ 학습목표
Neural Networks의 한 종류인 딥러닝(Deep Learning)에 대한 기본 개념과 대표적인 모형들의 학습원리를 배우게 됩니다.
이미지와 언어모델 학습을 위한 딥러닝 모델과 학습원리를 배우게 됩니다.
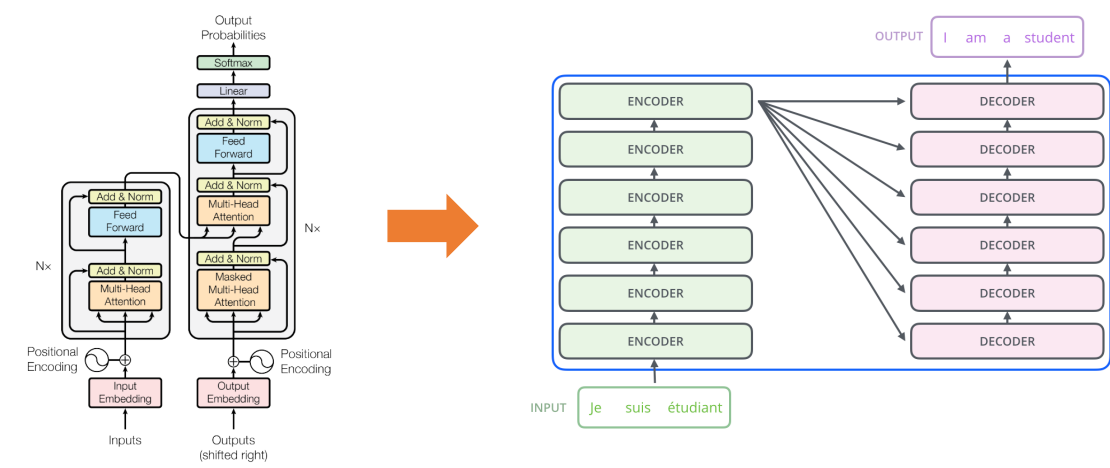
Part 5. Transformer
-How Transformer Model Works
-Review: Seq2Seq with Attention

-Transformer: High-level View
• Attention module can work as both a sequence encoder and a decoder in seq2seq with attention.
• In other words, RNNs or CNNs are no longer necessary, but all we need is attention modules.
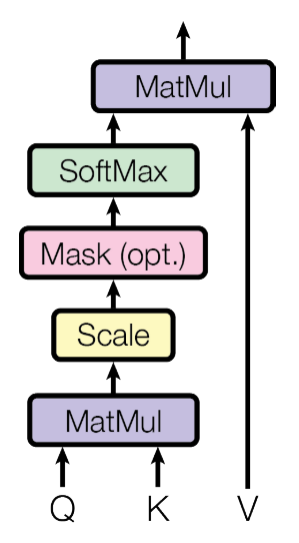
-Transformer: Scaled Dot-product Attention
• Problem
• As 𝑑𝑘 gets large, the variance of 𝑞^𝑇*𝑘 increases.
• Some values inside the softmax get large.
• The softmax gets very peaked.
• Hence its gradient gets smaller.
• Solution
• Scaled by the length of query / key vectors:

-Transformer: Multi-head Attention
• The input word vectors can be the queries, keys and values.
• In other words, the word vectors themselves select one another.
• Problem: only one way for words to interact with one another.
• Solution: multi-head attention maps 𝑄,𝐾, and 𝑉 into the ℎ number of lower-dimensional spaces via 𝑊 matrices.
• Afterwards, apply attention, then concatenate outputs and pipe through linear layer.
-Transformer: Block-Based Model
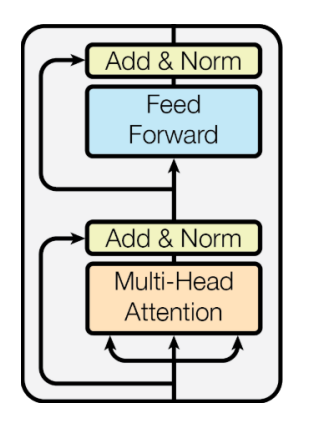
Each block has two sub-layers
• Multi-head attention
• Two-layer feed-forward NN (with ReLU)
Each of these two steps also has
• Residual connection and layer normalization:
LayerNorm(𝑥 + sublayer(𝑥))
-Layer Normalization
Layer normalization consists of two steps:
• Normalization of each word vectors to have zero mean of zero and variance of one.
• Affine transformation of each sequence vector with learnable parameters.
-Transformer: Positional Encoding
• Use sinusoidal functions of different frequencies:
𝑃𝐸(pos,2𝑖) = sin(pos/10000^2𝑖/𝑑 model)
𝑃𝐸(pos,2𝑖+1) = cos(pos/10000^2𝑖/𝑑 model)
• Easily learn to attend by relative position, since for any fixed offset 𝑘, 𝑃𝐸(pos+𝑘) can be represented as linear function of 𝑃𝐸 pos
• Another positional encoding can also be used (e.g., positional encoding in ConvS2S).
-Transformer: Warm-up Learning Rate Scheduler
• learning rate = 𝑑^−0.5model⋅ min(#step^−0.5
, #step ⋅ warmup_step−1.5)
-Transformer: Encoder Self-attention Visualization
• Words start to pay attention to other words in sensible ways.
-Transformer: Decoder
• Two sub-layer changes in decoder
• Masked decoder self-attention on previously generated outputs:
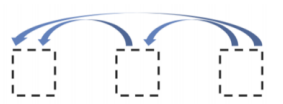
• Encoder-Decoder attention,
where queries come from previous decoder layer and keys and values come from output of encoder
-Transformer: Masked Self-attention
• Those words not yet generated cannot be accessed during the inference time.
• Renormalization of softmax output prevents the model from accessing not yet
generated words.
-Recent Trends
• Transformer model and its self-attention block has become a general-purpose
sequence (or set) encoder in recent NLP applications as well as in other areas.
• Training deeply stacked Transformer models via a self-supervised learning
framework has significantly advanced various NLP tasks via transfer learning, e.g.,BERT, GPT-2, GPT-3, XLNet, ALBERT, RoBERTa, Reformer, T5, …
• Other applications are fast adopting the self-attention architecture and selfsupervised learning settings, e.g., computer vision, recommender systems, drug
discovery, and so on
• As for natural language generation, self-attention models still require a greedy
decoding of words one at a time.
'코딩 도구 > LG Aimers' 카테고리의 다른 글
| LG Aimers 4기 B2B 시장, 소비자와 고객의 차이 (6) | 2024.01.24 |
|---|---|
| LG Aimers 4기 Self-Supervised Learning & Large-Scale Pre-Trained Models (3) | 2024.01.23 |
| LG Aimers 4기 Seq2Seq , Natural Language Understanding and Generation (2) | 2024.01.21 |
| LG Aimers 4기 Convolutional Neural Networks and Image Classification (5) | 2024.01.20 |
| LG Aimers 4기 Training Neural Networks (3) | 2024.01.19 |