2024. 1. 6. 17:14ㆍ코딩 도구/LG Aimers
LG Aimers: AI전문가과정 4차
Module 3. 『Machine Learning 개론』
ㅇ 교수 : 서울대학교 김건희
ㅇ 학습목표
본 모듈은 Machine Learning의 기본 개념에 대한 학습 과정입니다. ML이란 무엇인지, Overfitting과 Underfitting의 개념, 최근 많은 관심을 받고 있는 초거대 언어모델에 대해 학습하게 됩니다.
Bias and Variance

-Formal Definitions of ML

-Strongly related to the concept of overfitting
Overfitting = poor generalization
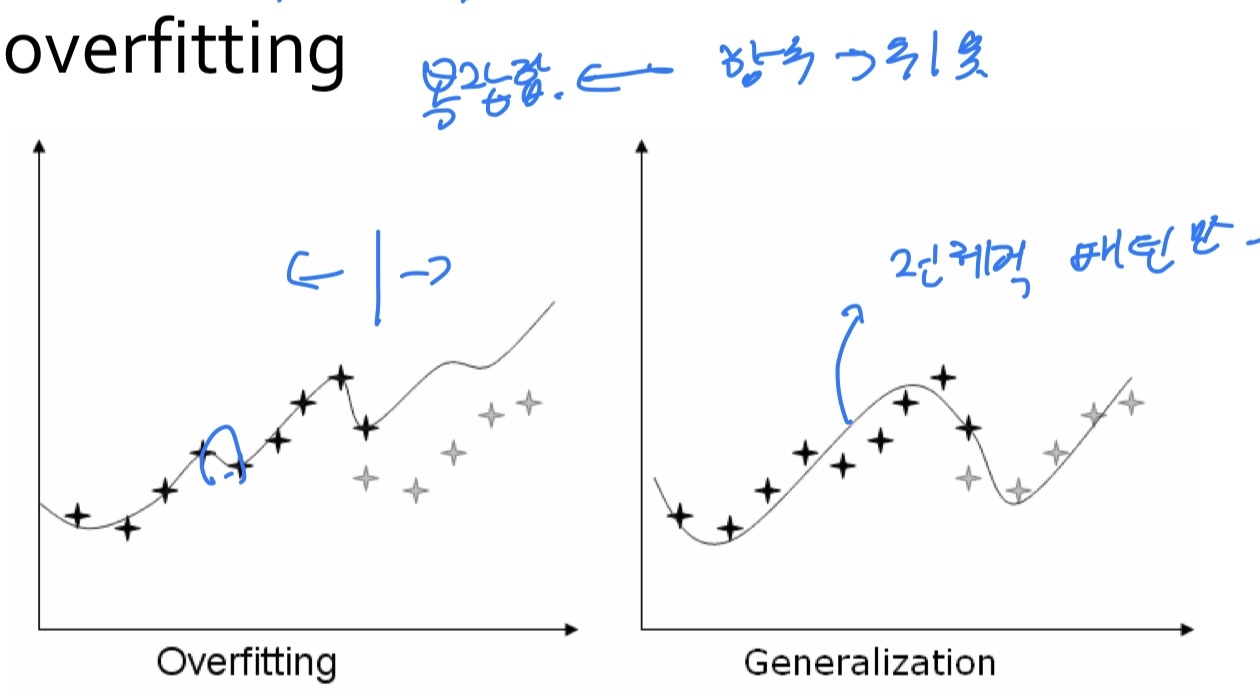
-Occam’s Razor (A Principle of Parsimony)
• All things being equal, the simplest solution tends to be the best one
• The simplest explanation tends to be the right one
어떤 사실 또는 현상에 대한 설명들 가운데 논리적으로 가장 단순한 것이 진실일 가능성이 높다는 원칙을 의미한다.
-Typical Relation between Capacity and Error
• Informally, a capacity is the function’s ability to fit a wide variety of functions
• As capacity increases, training errors decreases but the gap increases
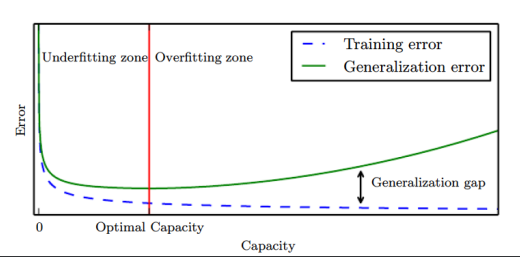
-Regularization
The main objective of regularization is to reduce its generalization error but not its training error
-Trade-off between Bias and Variance
Two sources of error in an estimator: bias and variance
• e.g., weight decay in a linear regression
(Test Error) = (Bias) + (Variance)
• Bias: Expected deviation from the true value of the function
• Variance: Deviation from the expected estimator values obtained from the
different sampling of the data
• Increasing capacity tends to increase variance and decrease bias
-Bias/Variance Decomposition
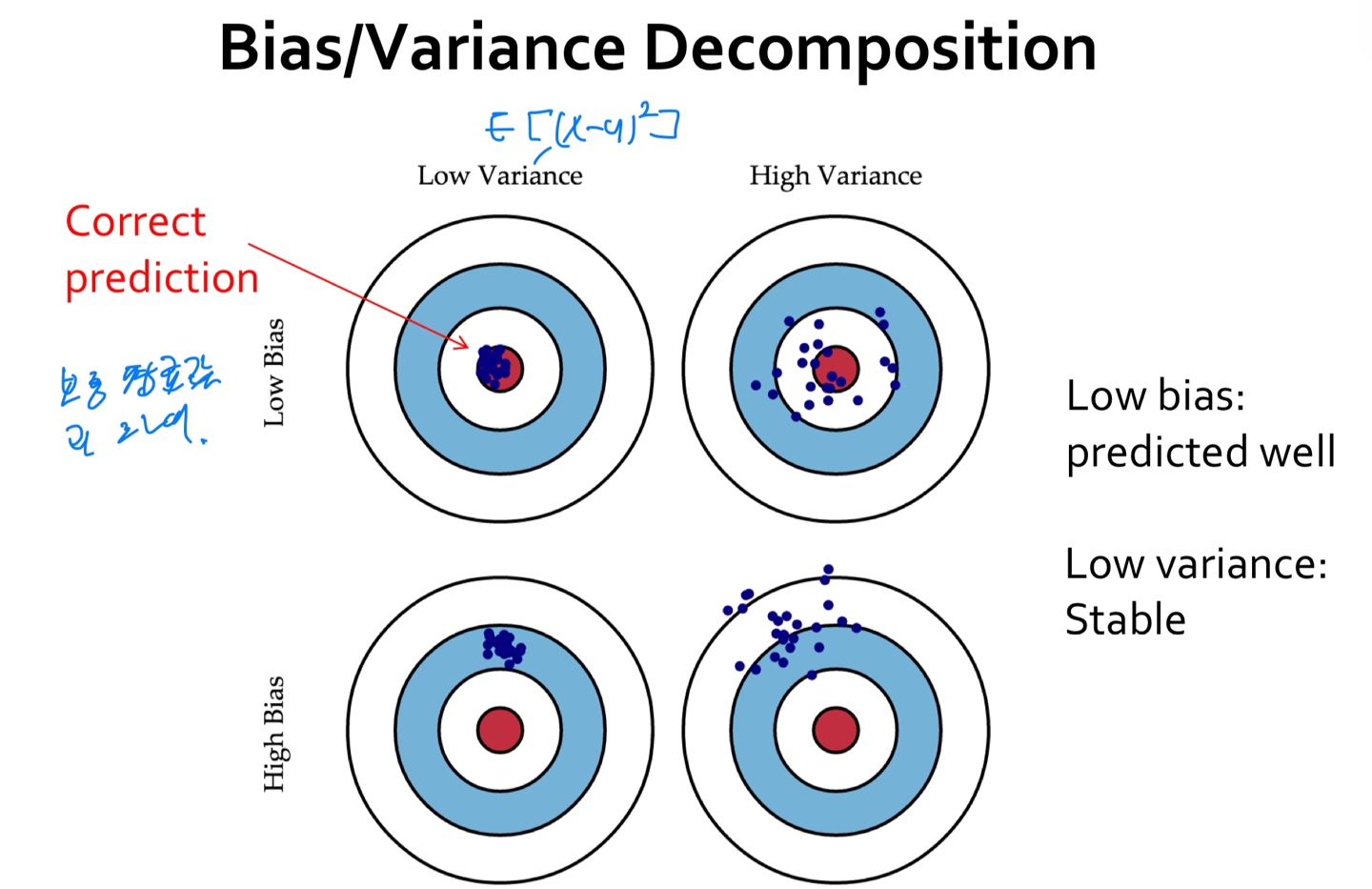
-High variance implies overfitting
• Model class unstable
• Variance increases with model complexity
• Variance reduces with more training data
-High bias implies underfitting
• Even with no variance, model class has high error
• Bias decreases with model complexity
• Independent of training data size
'코딩 도구 > LG Aimers' 카테고리의 다른 글
| LG Aimers 4기 그리고 지도학습(Supervised Learning) (2) | 2024.01.09 |
|---|---|
| LG Aimers 4기 그리고 GPT의 발전 (0) | 2024.01.07 |
| LG Aimers 4기 그리고 머신러닝의 목표는 ? (0) | 2024.01.05 |
| LG Aimers 4기 그리고 머신러닝을 위한 수학, Optional Course (2) | 2024.01.05 |
| LG Aimers 4기 그리고 세계적인 데이터 과학자 관련 사례 (4) | 2024.01.04 |